The State of Play: The Great AI Labelling Act
The current landscape of the Exchange Traded Fund (ETF) industry is best characterized as a Gold Rush mentality toward launching an actively managed ETF. As of 2026, the marketplace is saturated with such products. Historically most investors bought ETFs as passive funds tracking indices, but those days are long gone, and we shouldn’t be surprised to learn that active managers are increasingly alluding to using AI as part of their stock selection process.
Many of us have been dazzled by Claude’s Co-Worker tool as it makes light work of the most mundane and time-consuming tasks. Likewise, who’s not going to be impressed by one of Algo-Chain’s party tricks where one can load up an image of a list of ETFs and instantly turn that into a performance chart of all the funds included in that list. But exactly how are active managers using AI to generate Alpha? In a world at marketing spin, it’s time to pay more attention to what exactly the next generation of market wizards are up to.
With Google’s Anti Gravity AI app and other AI tools at their disposal, there’s every reason to believe that the current generation of quants do genuinely have a head start when it comes to developing very sophisticated trading strategies.
In this week’s newsletter we take a high level visit to the topics of Information Theory and Machine Learning Models, both of which provide the mathematical foundation, but which today’s AI revolution is built. Our mission is a modest one, and that is to start the journey of familiarizing ourselves with these subjects in preparation for those sales teams and marketing brochures that make bold claims about their firm’s AI capabilities. Let’s all raise our game by learning more about what they are talking about.
Claude Shannon and the Architecture of Uncertainty
To truly kick the tires on a modern AI-driven investment claim, we must look past the sleek user interfaces of today and examine the mathematical bedrock upon which they are built. The journey to sophisticated asset management AI does not begin with modern GPUs, but rather with a humble paper written in the aftermath of World War II.
In 1948, a mathematician and electrical engineer at Bell Labs named Claude Shannon fundamentally changed how we quantify the world. Before Shannon, information was a vague, qualitative concept, usually tied to semantics or human meaning. Shannon’s genius lay in divorcing meaning from measurement. He postulated that information had nothing to do with what a message said, but rather with what a message excluded. By treating information as a measurable statistical property, independent of its content, his seminal work, "A Mathematical Theory of Communication," effectively birthed the field of Information Theory. He transformed knowledge from an abstract idea into a tangible, physical quantity.
Shannon provided the standard unit of measurement for this new discipline: the bit. He defined information content by the degree of surprise it conveyed to the receiver. An event that is certain to happen conveys zero information because it reduces zero uncertainty. Conversely, a highly improbable event conveys maximum information because it drastically alters the receiver's state of knowledge. This breakthrough allowed Shannon to devise the mathematical tool to quantify Entropy: the universal measure of the average uncertainty or randomness in any given system.
This concept maps with chilling precision to financial markets, providing a rigorous mathematical framework to understand price movements. The fundamental debate of active management is, essentially, an information-theoretic argument. The Efficient Market Hypothesis (EMH), popularized later by Eugene Fama, posits that asset prices operate at or near maximum entropy. In this state, prices perfectly reflect all available knowledge, rendering them purely random walks. If a market exists in a state of maximum entropy, daily price changes are akin to the output of a perfect random number generator; no amount of historical data can predict the future state, because the historical data contains no remaining uncertainty to resolve.
For active managers, the singular, defining goal is to find order within this entropic disorder. However, without Shannon’s logic, analysing data is often just a process of finding spurious patterns - hallucinating signals where none exist. Information Theory provides the precise mathematical language to measure exactly how much noise (random, high-entropy, non-predictive fluctuations) exists in a financial time series and, crucially, how to separate it from predictive signal.
This is achieved primarily through the calculation of Mutual Information. Unlike standard linear correlation, which only measures if two variables move together, Mutual Information quantifies the reduction in the entropy of one variable (future stock returns) achieved by observing another variable (a specific economic indicator or alternative data point). It answers the vital question: how many bits of uncertainty regarding tomorrow’s price are resolved by observing today's indicator? If two variables share zero mutual information, they are mathematically independent, regardless of what a backtest might suggest.
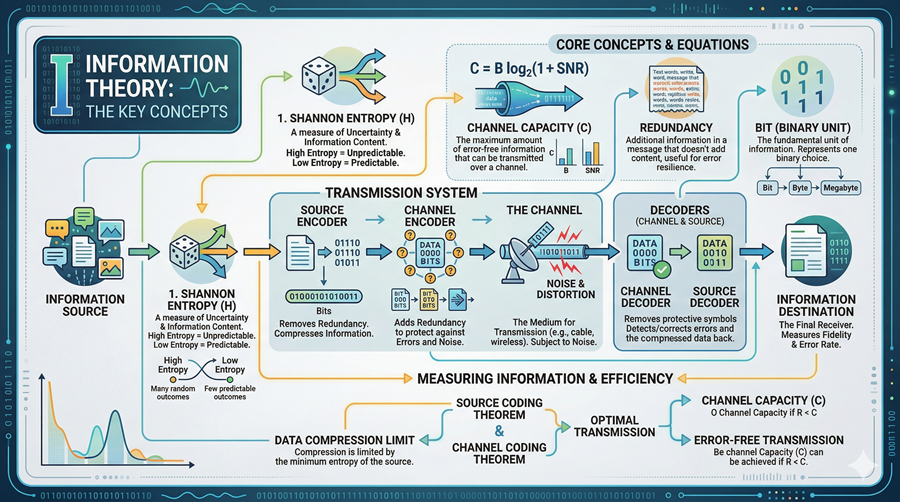 Figure 1 – Key concepts from Information Theory: entropy, channel capacity, mutual information.
Figure 1 – Key concepts from Information Theory: entropy, channel capacity, mutual information.
Generating alpha, therefore, is not so much about having more data or faster computers, but fundamentally, an operational implementation of Shannon's logic. It is a technological and mathematical race to navigate a high-entropy ocean of chaos, accurately measure the precise bit rate of specific data sources, and filter out the overwhelming noise to isolate the few, low-entropy bits of predictive signal that remain.
The Evolution of Learning: From Regressions to Reasoning
While Information Theory provided the definitive mathematical language to measure signal, noise, and uncertainty, Machine Learning (ML) arose as the dynamic, computational muscle required to actually extract that signal from high-entropy data. If Shannon defined the limits of what could be known, Machine Learning became the toolkit for how we come to know it mathematically.
The historical journey of ML is often mapped not as a pursuit of conscious intelligence, but as a relentless drive toward functional approximation. Conceptually, this is an optimization problem: finding the precise mathematical equations, however complex, that best fit clouds of erratic, high-dimensional data points to minimize prediction error. In the mid-20th century, this began crudely. Early quantitative analysts, relying on statistical methods developed in the pre-computing era, utilized simple linear regressions. Fundamentally, this was an exercise in extreme simplification, drawing a best-fit straight line through a two-dimensional scatter plot to quantify the relationship between, for example, a stock’s current Price-to-Earnings ratio and its subsequent twelve-month return.
However, these low-capacity, linear models rested on an assumption of Gaussian (normal) distributions, an assumption that financial reality routinely shatters. Financial markets do not move in straight lines; they are rife with reflexivity, regimes that shift without warning, and complex, non-linear dependencies. A linear model cannot capture a relationship where Factor A is highly predictive when volatility is low but completely irrelevant when volatility spikes. The inability of rigid, geometric formulas to adapt to market chaos necessitated models with higher model capacity - architectures capable of learning and representing intricate, jagged, and shifting boundaries in data.
This imperative led to the emergence of connectionist models, or Artificial Neural Networks, which sought to shift the paradigm from rigid curve-fitting to adaptive pattern recognition. The foundational conceptual breakthrough arrived in the late 1950s with Frank Rosenblatt’s Perceptron. Developed at the Cornell Aeronautical Laboratory, the Perceptron was the first truly operational artificial neuron. It was a simplified computational artifact inspired by the biological processes of the human brain’s neocortex. Critically, it took multiple binary inputs, multiplied them by adjustable weights, summed them, and passed the result through an activation function to produce an output.
The Perceptron promised a revolution: a machine that did not need to be programmed with rigid rules, but could instead learn iteratively via gradient descent, adjusting its internal weights based on past mistakes to improve future predictions. However, the path was not linear. Single-layer perceptrons, while potent in theory, were plagued by the exclusive or (XOR) problem - they were mathematically incapable of solving even basic non-linear logic gates, a limitation famously highlighted by Marvin Minsky and Seymour Papert in 1969.
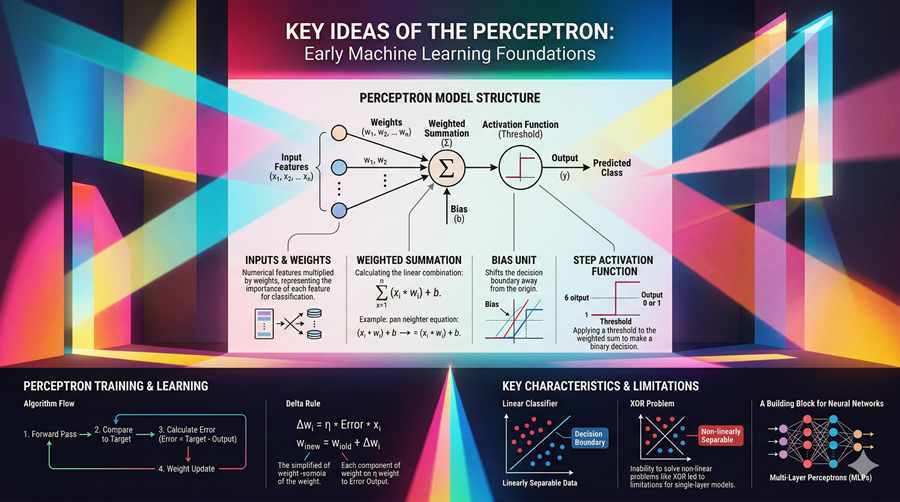 Figure 2 – The Perceptron: the conceptual building block for modern neural networks and their training flow.
Figure 2 – The Perceptron: the conceptual building block for modern neural networks and their training flow.
This limitation, combined with a lack of computational power and massive datasets, plunged the field into the first of several AI Winters. Theoretical ambition had outpaced silicon reality. For decades, the field languished in financial obscurity, until a resurgence in the 1980s driven by the formalization of Backpropagation. This algorithm was the vital innovation that the Perceptron lacked. Backpropagation utilized the chain rule of calculus to efficiently propagate error backwards from the output layer, through hidden layers, to adjust the weights of earlier neurons. This breakthrough allowed for the effective training of multi-layered, deep networks, enabling the computational muscle to finally grasp the non-linear complexities that traditional finance had long ignored.
Today's Sophisticated State: The Statistical Mirror
This historical convergence of mathematical theory and computational muscle has brought us to the sophisticated, high-stakes state of play we witness in 2026. Machine Learning and Information Theory are no longer separate, adjacent fields; they have merged to become two sides of the same algorithmic coin. In this unified paradigm, a machine learning model is essentially an optimization engine designed to minimize an information-theoretic loss function. Modern AI learns by employing Shannon’s concepts to rigorously measure its own standard of error.
The primary mechanism for this learning is often a metric called Cross-Entropy Loss. Fundamentally, this is a measure of surprise. The model compares its predicted probability distribution (its guess about future price movements) against the actual, true distribution observed in the market data. Cross-Entropy quantifies the average number of bits needed to identify an event from the true distribution if we use the wrong, predicted coding scheme. By utilizing gradient descent to minimize this loss, the AI iteratively adjusts its internal weights and biases - its logic - to maximize information gain, thereby aligning its internal model with the chaotic reality of the market.
Today's elite boutique quant shops have leveraged this convergence to move far beyond standard factor investing or simple trend-following. They are no longer just fitting rigid lines to sparse data points; they are employing high-capacity Deep Learning architectures. These multi-layered, non-linear models do not view data as flat tables, but rather as high-dimensional vector spaces, mapping complex, subtle dependencies that traditional statistics completely miss.
It is this specific convergence of measuring signal capacity (Shannon) and acting upon it adaptively (Machine Learning) that fuels the impressive modern toolsets. Within these sophisticated architectures are specialized mechanisms, such as Attention Mechanisms (the engine behind Transformer models), which allow the AI to solve the rigidity of previous linear approaches. Theoretically, these attention-based models can dynamically down-weight the high-frequency noise of a minor quarterly earnings miss if the low-frequency signal of a broader macro-economic shift - perhaps detected via alternative natural language processing (NLP) data - is more statistically dominant. This synthesis transforms AI from a mere curve-fitting tool into a sophisticated search for fundamental, algorithmic order within the market's high-entropy chaos.
Applying Information Theory to Market Hype
We have reached a critical inflection point in the AI adoption cycle. The period of magical thinking, where the mere mention of an algorithm sufficed to attract capital, is ending. As computing power becomes a commodity, the differentiator is no longer the simple possession of a model, but the mathematical logic governing it. While marketing fluff relies on a black-box mystique, the current market regime demands a transition toward true information efficiency. We must move beyond asking what an AI fund owns and start asking how much uncertainty its model removes from the investment process.
We can utilize the concepts of Information Theory to build a theoretical Alpha Detector to audit actively managed funds. Instead of fixating solely on performance, which can be conflated by luck, we analyse the Conditional Entropy of the returns. This quantifies how much uncertainty remains in the fund’s returns once we already know the state of the broad market.
If a fund's returns are perfectly correlated with the S&P 500, its Mutual Information with the market will be nearly identical to its own entropy. This mathematically unmasks the Closet Indexer - a fund providing no unique information and, consequently, no true alpha. A skilled model, by contrast, generates order from disorder. It produces a return stream that is highly compressible, meaning it is defined by a persistent, simple logic rather than high-entropy, random events.
Traditionally, the investment industry relies on Active Share - quantifying how much a manager’s allocations differ from a benchmark - to detect index hugging. By measuring the bit rate of a manager’s edge via information theory, we can mathematically separate skilful signal from lucky beta noise, providing a robust alternative to Active Share.
Crucially, this check must be averaged over several periods. There are times when the data suggests that investing in mega-cap companies is the optimal strategy, resulting in a high benchmark correlation. We should not penalize managers for valid broad-market exposure; however, a long-term entropic audit will reveal whether a manager possesses a distinctive edge or is simply collecting fees for beta.
The Entropic Limit: The Impossibility of Persistent Alpha
Ultimately, we must confront a sobering possibility: that persistent, long-term alpha is a mathematical impossibility in a competitive environment. This is the financial equivalent of the Heat Death of the universe. If an AI model discovers a predictable, straight-line signal in the market, it will exploit it. However, the very act of exploiting that signal - buying the undervalued and selling the overvalued - inevitably drives the price toward efficiency.
As more AI models enter the fray, they compete to consume the same finite bits of information. This process ruthlessly increases the entropy of the remaining signal until the alpha is exhausted - a phenomenon known as Alpha Decay. Devising a model that delivers persistent alpha requires outrunning the second law of thermodynamics; patterns begin to dissolve back into noise the moment they are identified and actioned. While increasingly sophisticated AI allows us to approach the limit of perfect returns, in a reflexive, entropic market, that straight line remains a destination we can never truly reach.
Until next time.
Allan Lane